分布式缓存出于如下考虑,首先是缓存本身的水平线性扩展问题,其次是缓存大并发下的本身的性能问题,再次避免缓存的单点故障问题(多副本和副本一致性)。分布式缓存的核心技术包括首先是内存本身的管理问题,包括了内存的分配,管理和回收机制。其次是分布式管理和分布式算法,其次是缓存键值管理和路由。
Memcached要想实现分布式只能在客户端来完成,目前比较流行的是通过一致性hash算法来实现。首先求出memcached服务器(节点)的哈希值, 并将其配置到0~232的圆(continuum)上。 然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。 如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。在Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的 第一台服务器上的键会受到影响。
关于一致性hash,再盗图一张。
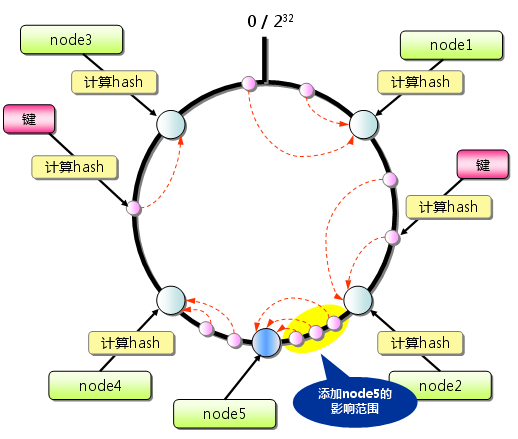
因此,Consistent Hashing最大限度地抑制了键的重新分布。 而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想。 使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。 因此,使用虚拟节点的思想,为每个物理节点(服务器) 在continuum上分配100~200个点。这样就能抑制分布不均匀, 最大限度地减小服务器增减时的缓存重新分布。
摘自:http://blog.sina.com.cn/s/blog_493a845501013ei0.html